![]()
![]()
Bạn có chắc chắn muốn xóa bài viết này không ?
Bạn có chắc chắn muốn xóa bình luận này không ?
Có thể bài viết dưới đây chưa hoàn toàn là đầy đủ nhưng cũng khá là bổ ích cho những bạn chưa được tiếp cận hay tham gia thiết kế kiến trúc của hệ thống hoặc các bạn đang muốn nắm lại tổng quan về kiến trúc web.
Lướt trên Grokking VN group fb thấy có chia sẻ 1 bài về architecture thường thấy của các web hiện nay ( https://engineering.videoblocks.com/web-architecture-101-a3224e126947) mà tiện thế cũng là cuối tháng rồi :)).
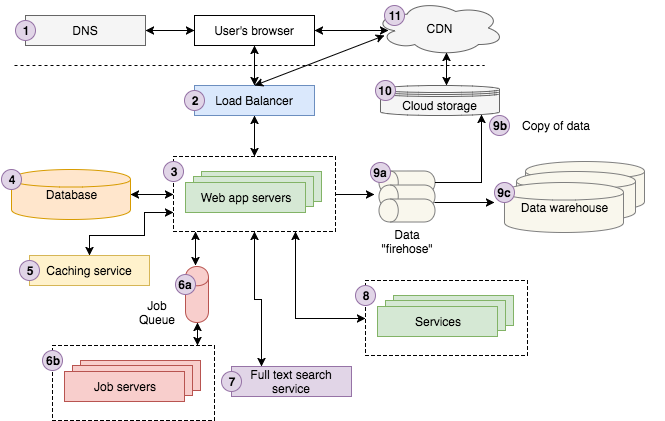
Trong bài viết này, tác giả cung cấp 1 diagram giới thiệu những thành phần cơ bản nhất trong kiến trúc web hiện đại cùng diễn giải tương ứng, các thành phần như datawarehouse, full text search, … đều được đề cập. Ok let's go...
Biểu đồ ở trên là một kiến trúc khá tốt tại Storyblocks (Vì tác giả bài viết Jonathan Fulton là SVP Product & Engineering tại StoryblocksCo). Nếu bạn không phải là nhà phát triển web có kinh nghiệm, bạn có thể thấy nó phức tạp. Việc đọc những kiến thức dưới đây sẽ giúp bạn dễ tiếp cận hơn trước khi chúng ta đi sâu vào chi tiết của từng thành phần.
Thực ra trong bài viết có mô tả về flow của hệ thống Storyblock nhưng mình thấy nó cũng được diễn giả đủ ở dưới rồi. Để giảm đi sự dài dòng thì mình lược bỏ đi. Bây giờ cũng tìm hiểu các thành phần nhé.
DNS là viết tắt của Domain Name System và nó là một công nghệ cốt lõi để mà kết nối các web trên toàn thế giới. Khái niệm cơ bản thì DNS cung cấp tra cứu key / value từ một tên miền (ví dụ: tên miền google.com) trỏ đến địa chỉ IP (ví dụ: 85.129.83.120), để khi máy tính của bạn gọi tới 1 tên miền thì sẽ được định tuyến request đó đến địa chỉ IP phù hợp (server). Nó giống như bạn cần một danh bạ điện thoại để tra cứu số vậy, bạn cần DNS để tra cứu địa chỉ IP cho một tên miền. Vì vậy, bạn có thể nghĩ DNS là danh bạ điện thoại cho internet. Có nhiều chi tiết hơn về DNS nhưng đây chỉ là giới thiệu về cơ bản thôi nhé.
Trước khi nói chi tiết về load banlancing, chúng ta cần thảo luận lại về việc horizontal scaling (scale theo chiều ngang) và vertical scaling(scale theo chiều dọc). Sự khác nhau? Bạn có thể tham khảo thêm từ StackOverflow post này nhé. Ngắn gọn thì horizontal scaling là scale bằng cách thêm/giảm các servers ở cụm server. Trong khi đó vertical scaling thì sẽ thêm/giảm các tài nguyên (CPU, RAM,...) cho các máy chủ đang tồn tại.
Secondly, horizontal scaling allows you to minimally couple different parts of your application backend (web server, database, service X, etc.) by having each of them run on different servers.
Trong việc phát triển web, chúng ta luôn luôn muốn scale horizontally bởi vì nó đơn giản:
"fault tolerant". Tức là máy chủ crash ngẫu nhiên, network bị downtime, hay data center bị offline. Khi scale ra nhiều máy chủ, đặt ở nhiều zone cho phép bạn lên kế hoạch, để giữ cho ứng dụng tiếp tục chạy (đảm bảo available).minimum được chi phí cho các service. Kiểu như không nhất thiết phải chạy 4 servers cả ngày mà nó sẽ scaling về 2 server chẳng hạn.cấu hình bị giới hạn. Hoặc máy vật lý thì cũng sẽ bị giới hạn nếu bạn không thay đổi cấu trúc server vậy lý. Vì lẽ đó ta phải kết hợp nó với scaling horizontally.Quay trở lại với Load Balancer. Load balancer nhận tất cả các requests và định tuyến tới các application servers (các server mà được clone/ hoặc images giống nhau). Và gửi response từ các app server về lại clients. Bất kỳ clients nào cũng nên xử lý request theo cùng một cách, để đảm bảo việc phân phối theo thuật toán để các máy chủ không bị quá tải. Nó có khả năng kết hợp với scaling horizontally để đảm bảo lượng app servers luôn đáp ứng đủ.
You should know that app server implementations require choosing a specific language (Node.js, Ruby, PHP, Scala, Java, C# .NET, etc.) and a web MVC framework for that language (Express for Node.js, Ruby on Rails, Play for Scala, Laravel for PHP, etc.). However, diving into the details of these languages and frameworks is beyond the scope of this article.
Mô tả đơn giản thì các Web Application Servers để xử lý business logic từ các request của người dùng và gửi trả response (html, json, ...) về lại user browser. Để làm các công việc đó, thì nó cần giao tiếp với các thành phần backend infrastructure như: database, caching layers, job queues, search services, các microservices khác, data/logging queues, và ... Như đã đề cập ở trên, chúng ta thường có ít nhất hai lần servers cắm vào load balancers để xử lý các requests của người dùng.
Bạn nên biết các thành phần được implement vào app server với từng ngôn ngữ, nền tảng (Nodejs, Ruby, PHP, Scala, Java, C#, .NET, ...) và một web MVC framework cho các ngôn ngữ/nền tảng trên (mình sử dụng cả chữ nền tảng vì ngoài các ngôn ngữ thì Nodejs là nền tảng). Tuy nhiên để đi sâu chi tiết vào các ngôn ngữ hay framework thì không nằm trong scope của bài này.
Mỗi ứng dụng web hiện đại tận dụng một hoặc nhiều database để lưu trữ dữ liệu. Database cung cấp các cách truy vấn, tạo mới, cập nhất hay thực hiện tính toán trên dữ liệu và hơn thế nữa. Trong hầu hết các trường hợp, các app servers giao tiếp trực tiếp với một database (hoặc một cụm database master-replicas, master-slave), các job servers cũng vậy. Ngoài ra, mỗi service có thể có database riêng độc lập với phần còn lại của ứng dụng.
2 loại database chính đề cập ở đây: SQL và NoSQL.
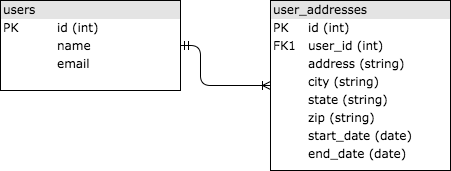
SQL là viết tắt của Structured Query Language, cung cấp một cách truy vấn tiêu chuẩn cho các bộ dữ liệu quan hệ có thể truy cập được đối tượng rộng. Cơ sở dữ liệu SQL lưu trữ dữ liệu trong các bảng được liên kết với nhau thông qua các khoá, điển hình là số nguyên. Ví dụ đơn giản về lưu trữ thông tin địa chỉ lịch sử cho người dùng. Bạn có thể có hai bảng, user và user_addresses, được liên kết với nhau bởi user_id. Các bảng được liên kết vì cột user_id trong user_addresses là một khóa ngoại tham chiếu cột id trong bảng users.
NoSQL, which stands for “Non-SQL”, is a newer set of database technologies that has emerged to handle the massive amounts of data that can be produced by large scale web applications (most variants of SQL don’t scale horizontally very well and can only scale vertically to a certain point). If you don’t know anything about NoSQL, I recommend starting with some high level introductions like these:
NoQuery, viết tắt của từ Non-SQL, là một bộ công nghệ cơ sở dữ liệu mới hơn, xuất hiện để xử lý lượng dữ liệu khổng lồ (large data) có thể được tạo ra bởi các ứng dụng web quy mô lớn (hầu hết các biến thể của SQL mở rộng theo chiều ngang không tốt và chỉ có thể mở rộng theo chiều dọc đến một điểm nhất định). Nếu bạn không biết gì về NoSQL, tôi khuyên bạn nên bắt đầu với một số tài liệu:
https://www.w3resource.com/mongodb/nosql.php
http://www.kdnuggets.com/2016/07/seven-steps-understanding-nosql-databases.html
https://resources.mongodb.com/getting-started-with-mongodb/back-to-basics-1-introduction-to-nosql
Môt caching service cung cấp đơn giản dạng dữ liệu key/value để lưu và lấy thông tin nhanh chóng trong một expire time nào đó. Các ứng dụng thường tận dụng các dịch vụ lưu trữ để lưu kết quả của các truy vấn hay tính toán phức tạp mất thời gian để có thể lấy lại kết quả từ bộ đệm (cache) thay vì phải truy vấn hay tính toán lại chúng vào lần tiếp theo khi chúng ta cần. Một ứng dụng có thể caching với việc lưu trữ kết quả từ truy vấn cơ sở dữ liệu, gọi đến các dịch vụ bên ngoài, HTML cho một URL nhất định và nhiều hơn nữa. Dưới đây là một số ví dụ từ các ứng dụng thực tế:
Hai công nghệ phổ biến nhất là Redis và Memcache. Có rất nhiều bài viết giúp bạn so sánh 2 công nghệ này. Với mình thì mình thường dùng Redis :)) bạn thử tham khảo ở đây nhé!
Hầu hết web applications cần làm các công việc bất đồng bộ ở backend, nó không tham chiếu trực tiếp đến response của request từ user. Ví dụ, Google cần crawl và đánh index toàn bộ internet để trả về kết quả tìm kiếm. Google không làm điều này mỗi khi bạn tìm kiếm. Thay vào đó, nó crawl dữ liệu web, cập nhật các chỉ mục tìm kiếm bằng cách chạy bất đồng bộ.
Trong khi có các kiến trúc khác nhau để áp dụng chạy các task bất đồng bộ, đa số thì sử dụng job queue. Nó bao gồm 2 components: 1 queue chứa các jobs messages cần chạy và 1 hoặc cụm job servers (thường gọi là worker servers) để chạy các jobs message trong queue. Job queues lưu 1 danh sách các jobs cần chạy bất đồng bộ. Đơn giản nhất là First In First Out (FIFO) queue. Tức là sắp sếp priority(độ ưu tiên) theo rule là: vào trước thì ra trước. Bất cứ lúc nào ứng dung cần 1 job để chạy, chỉ cần thêm 1 job message (là 1 message chỉ rõ action được thực hiện).
Ví dụ, Storyblock tận dụng sử dụng queue để đẩy rất nhiều jobs để thực hiện behind backend. Các tác vụ nặng như công việc để mã hóa video và ảnh, xử lý CSV, tổng hợp số liệu thống kê người dùng, gửi email đặt lại mật khẩu và hơn thế nữa. Storyblock đã bắt đầu với một FIFO queue đơn giản. Và Storyblock đã nâng cấp lên hàng đợi ưu tiên để đảm bảo rằng các job đặc biệt, độ ưu tiên cao được thực thi với thời gian ngắn mà không phải chờ đợi các message đến trước. Như gửi email đặt lại mật khẩu cần được hoàn thành càng sớm càng tốt.
Cách Job server xử lý jobs, nó sẽ theo dõi queue để xác định xem có jobs nào không, và dựa theo priority để thực hiện job nào đó. Sau khi thực hiện xong logic của jobs, thì job message đó sẽ bị loại bỏ khỏ job queue. Đây là trình bày theo 1 cách đơn giản, các bạn hay tìm hiểu sâu hơn nhé!
Đa số các ứng dụng web đều hỗ trợ chức năng tìm kiếm, trong đó người dùng cung cấp kiểu nhập 1 văn bản (thường được gọi là truy vấn trực tuyến). Công nghệ cung cấp chức năng này được gọi là "full-text-search", có thể sử dụng một inverted index để tìm kiếm nhanh các tài liệu có chứa các từ khóa truy vấn.
Mặc dù có thể thực hiện tìm kiếm toàn văn bản trực tiếp từ một số cơ sở dữ liệu (ví dụ: MySQL hỗ trợ tìm kiếm toàn văn bản), Nhưng để đạt performacne cao với dữ liệu lớn thì ta có thể chạy một dịch vụ tìm kiếm riêng biệt, tính toán và lưu trữ inverted index và cung cấp query interface. Nền tảng tìm kiếm toàn văn bản phổ biến nhất hiện nay là Elaticsearch mặc dù có các tùy chọn khác như Sphinx hoặc Apache Solr.
Khi một ứng dụng đạt đến một quy mô nhất định, có khả năng sẽ có một số dịch vụ nhất định được để chạy như các ứng dụng riêng biệt. Các ứng dụng này không giao tiếp với thế giới bên ngoài (tức là không public) được sử dụng bởi các ứng dụng khác qua 1 cơ chế authen. Ví dụ như với Storyblocks, có một số service như:
Việc khai thác dữ liệu rất quan trọng. Hầu như mọi ứng dụng ngày nay, một khi nó đạt đến một quy mô nhất định, tận dụng data pipeline (quy trình dữ liệu) để đảm bảo rằng dữ liệu có thể được thu thập, lưu trữ và phân tích. Với Storyblocks một data pipeline điển hình có ba giai đoạn chính:
firehose, nơi cung cách thức streaming để nhập và xử lý dữ liệu. Thông thường, dữ liệu thô được chuyển đổi hoặc biến đổi và chuyển tới 1 service khác. Các firehose như AWS Kinesis và Kafka là hai công nghệ phổ biến nhất cho mục đích này.Cloud Storage. AWS Kinesis cung cấp một cấu hình có tên là firehose, giúp lưu dữ liệu thô vào Cloud storage (AWS S3) dễ dàng để cấu hình.AWS Redshift, cũng như một phần lớn các startup của thế giới, mặc dù các công ty lớn hơn sẽ thường sử dụng Oracle hoặc các warehouse độc quyền khác. Nếu các bộ dữ liệu đủ lớn, một Hadoop giống như công nghệ NoSQL MapReduce có thể được yêu cầu để phân tích.Một phần nữa chưa được mô tả trong architecture diagram ở trên: tải dữ liệu từ app và database của services tới data warehouse. Ví dụ: tại Storyblocks, chúng tôi tải VideoBlocks, AudioBlocks, Storyblocks, Account service và cơ sở dữ liệu của contributor portal (cổng thông tin đóng góp ý kiến) vào Redshift mỗi đêm. Điều này cung cấp cho các nhà phân tích của chúng tôi một bộ dữ liệu tổng thể để phục vụ mục đích phân tích người dùng và kinh doanh.
Cloud Storage là cách đơn giản và scalable để lưu trữ, truy cập và chia sẻ data trên internet. Với AWS cloud, Bạn có thể sử dụng nó để lưu trữ và truy cập bất cứ thứ gì bạn lưu trữ trên hệ thống, lợi ích là có thể tương tác với nó thông qua API RESTful qua HTTP. Cung cấp Amazon S3 cho đến nay là nơi cloud storage phổ biến nhất hiện nay và là nơi chúng tôi sử dụng rộng rãi tại Storyblocks để lưu trữ video, image và audio, CSS và Javascript, dữ liệu sự kiện người dùng và nhiều hơn nữa.
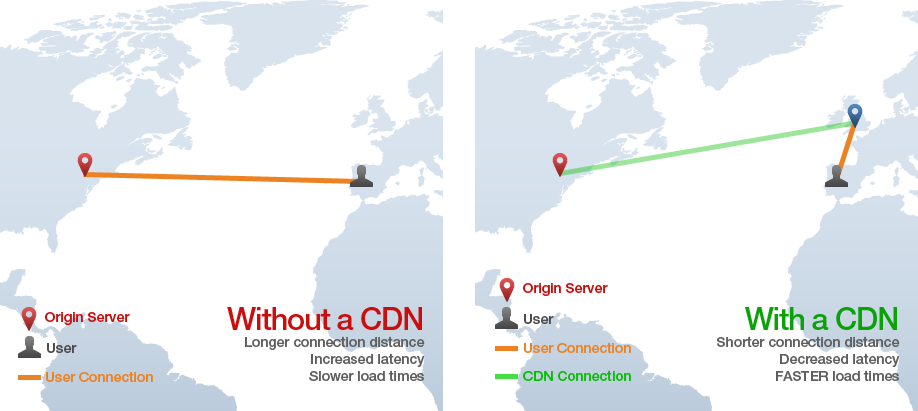
CDN viết tắt của “Content Delivery Network” and the technology provides a way of serving assets such as static HTML, CSS, Javascript, and images over the web much faster than serving them from a single origin server. It works by distributing the content across many “edge” servers around the world so that users end up downloading assets from the “edge” servers instead of the origin server. For instance in the image below, a user in Spain requests a web page from a site with origin servers in NYC, but the static assets for the page are loaded from a CDN “edge” server in England, preventing many slow cross-Atlantic HTTP requests.
và là công nghệ cung cấp cách serving các assets như static HTML, CSS, Javascript và image trên web nhanh hơn nhiều so với việc phục vụ chúng từ một origin server. Nó hoạt động bằng cách phân phối nội dung trên nhiều Edge server đặt trên toàn thế giới để end user tải xuống các asset này từ các edge server vị trí địa lý gần nó nhất thay vì tận origin server.
Ví dụ trong hình ảnh bên dưới, một người dùng ở Tây Ban Nha request một trang web có origin server ở NYC, nhưng static asset cho trang được tải từ CDN edge server, ở Anh, ngăn chặn nhiều HTTP request chậm từ bên kia Đại Tây Dương.
Nói chung, một ứng dụng web mang tính toàn cầu, phải luôn sử dụng CDN để phục vụ CSS, Javascript, image, video và bất kỳ asset nào khác. Một số ứng dụng cũng có thể tận dụng CDN để phục vụ các web static HTML để truy vấn toàn cầu nhanh hơn.
Và trên đây là giới thiệu cơ bản các thành phần của Web Architecture. Bài viết dựa trên kiến trúc của Storyblocks product của tác giả Jonathan Fulton đáng để chúng ta tham khảo dù có thể thực tế mô hình của chúng ta sẽ có nhiều khác biệt. Ở đây cũng là những chú ý cơ bản để các bạn mới làm quen về backend cũng như thiết kế hệ thống từ đó tự research sâu hơn về các note này. Cảm ơn mọi người đã đọc tới đây :D